POSTS
Problems with intuitive availability calculations
I often see/hear comments from people whose common sense approach to availability design includes eliminating a single point of failure. This is a great goal when required, but care must be take that the “common sense” approach is actually achieving what is required. I have found that using a fault tree approach to evaluating design decisions can be insightful.
The last instance of this is a book, while otherwise great, gave the advice of separating a database from the application function onto separate servers because there was a single point of failure. This advice works when the components are not related, but not at all when they are dependent.
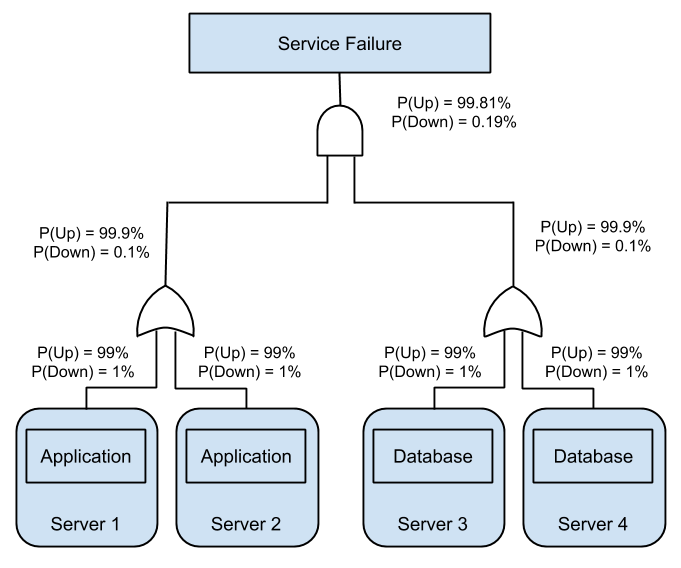
Here is an example analysis of an application on hardware that is 99% available.
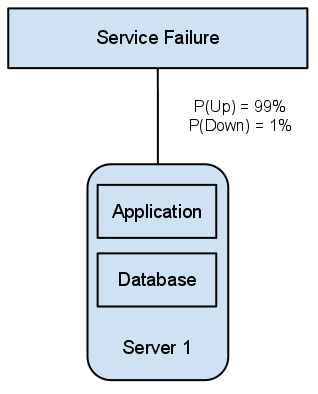
If we follow the advice of separating concerns to eliminate the single point of failure we end up with this picture.
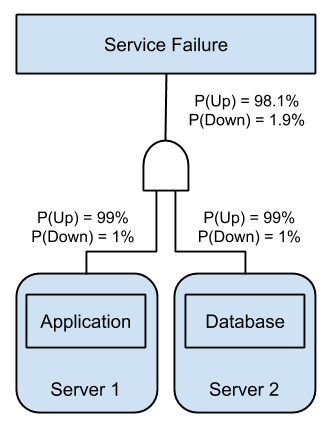
Unfortunately, based on the hardware availability, we have reduced the availability of the service. With a diagram it becomes apparent that the entire service is now at risk of failing when either of the two servers fail. This incorrect thought process also leads to the idea that consolidating an application onto fewer virtualized servers always leads to lower availability.
All of this is not to say that consolidation always provides higher availability. Here is an example of using a software stack that allows for multiple servers to serve the same purpose. This analysis is not exact as it leaves out the increased likelihood of software failure or human error, but in the simple case of hardware availability you can see a definite improvement.